apart sprints
Develop breakthrough ideas
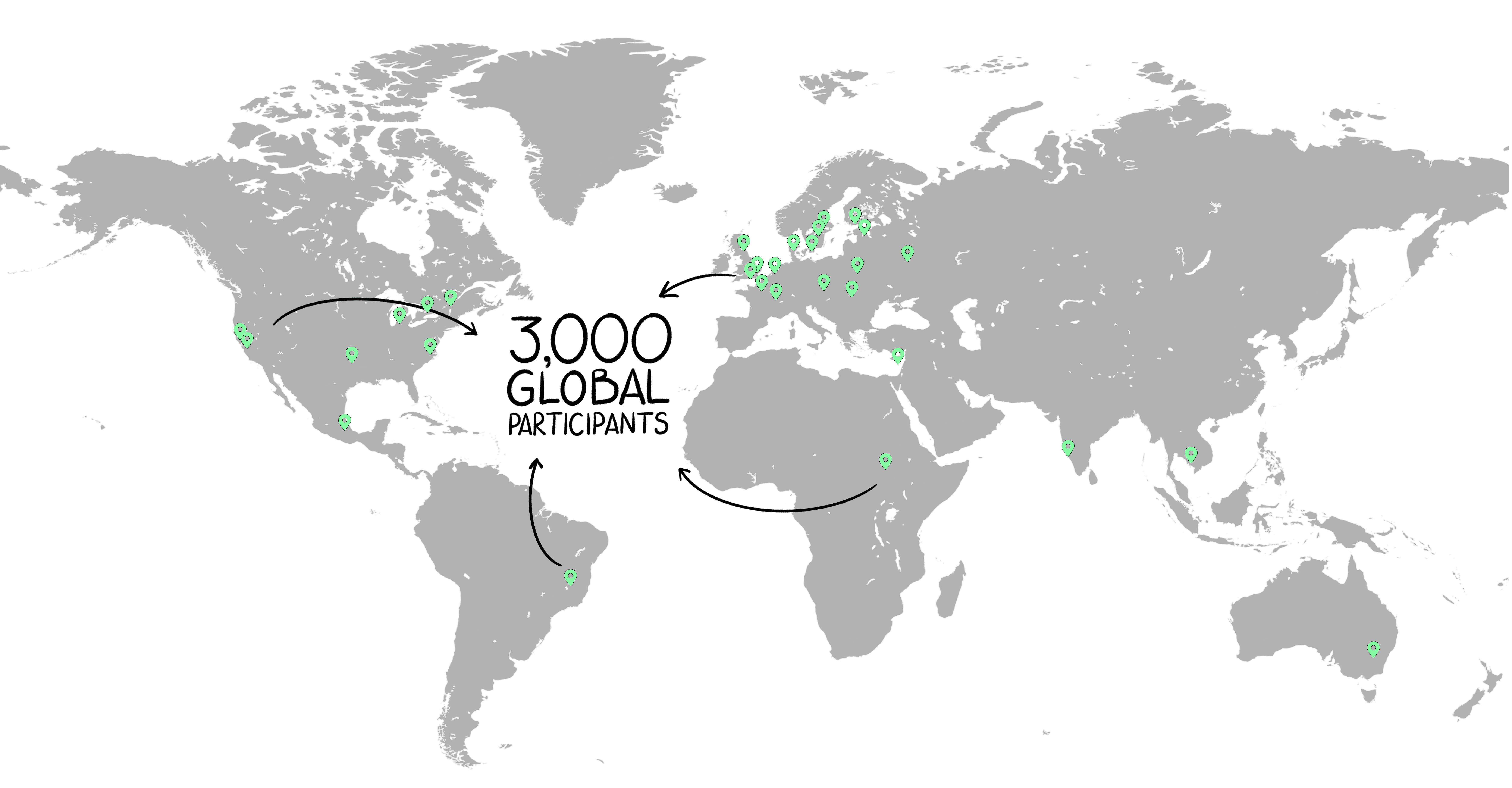
Join our monthly hackathons and collaborate with brilliant minds worldwide on impactful AI safety research

With partners and collaborators from







Independent Hackathons
2025-04-14
-
2025-04-26
Berkeley AI Policy Hackathon
The purpose of this hackathon is to provide a space for students to advocate for solutions to AI policy issues that many lawmakers and technologists are thinking about, both in California and beyond.
2025-04-05
-
2025-04-06
Georgia Tech AISI Policy Hackathon
Join the Georgia Tech AI Governance Hackathon and shape the future of AI policy! Collaborate with peers, experts, and mentors to develop innovative solutions for critical AI governance challenges. Whether you're a tech enthusiast, policy wonk, or ethical thinker, your ideas can make a real impact. Don't miss this opportunity to contribute to global AI safety and elevate Georgia Tech's role in the field. Register now and be part of the change!
Publications From Hackathons






Sprint Collaborations
Apr 25, 2025
-
Apr 27, 2025
Economics of Transformative AI
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Apr 14, 2025
-
Apr 26, 2025
Berkeley AI Policy Hackathon
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Apr 5, 2025
-
Apr 6, 2025
Georgia Tech AISI Policy Hackathon
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Apr 4, 2025
-
Apr 6, 2025
Dark Patterns in AGI Hackathon at ZAIA
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Mar 29, 2025
-
Mar 30, 2025
AI Control Hackathon 2025
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Mar 7, 2025
-
Mar 10, 2025
Women in AI Safety Hackathon
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible

